

AI workloads are rapidly moving from experimentation into production. Organizations are deploying inference services that must respond in real time, scale to unpredictable demand, and run reliably across environments.
Traditional infrastructure approaches are not always designed to support these requirements. Production AI systems require orchestration, automation, and scalable compute to efficiently manage GPU-intensive workloads.
Kubernetes has emerged as the standard platform for operating AI workloads in production. With its ability to orchestrate containers, manage distributed services, and scale dynamically, Kubernetes provides the control plane modern AI infrastructure requires.
Kubernetes as the control plane for AI
Kubernetes enables organizations to treat AI models like any other cloud-native service. Models can be packaged into containers, deployed across clusters, and scaled automatically based on demand.
Several capabilities make Kubernetes particularly well-suited for AI inference workloads.
Container orchestration for model services
AI models are typically deployed as containerized services. Kubernetes manages container scheduling, networking, and lifecycle management, ensuring models are consistently deployed and maintained.
Horizontal scaling for inference endpoints
Inference traffic can fluctuate significantly depending on application demand. Kubernetes allows teams to scale inference services automatically, adding or removing replicas based on load.
GPU scheduling and resource allocation
AI workloads require specialized compute resources. Kubernetes can schedule workloads onto GPU-enabled nodes, ensuring efficient utilization of high-performance infrastructure.
Multi-region deployment
Production AI systems often need global availability. Kubernetes clusters can run across multiple regions, enabling organizations to deploy inference services closer to users and reduce latency.
Together, these capabilities allow teams to create repeatable, automated pipelines for deploying and operating AI models.
Running AI inference with Vultr and Baseten
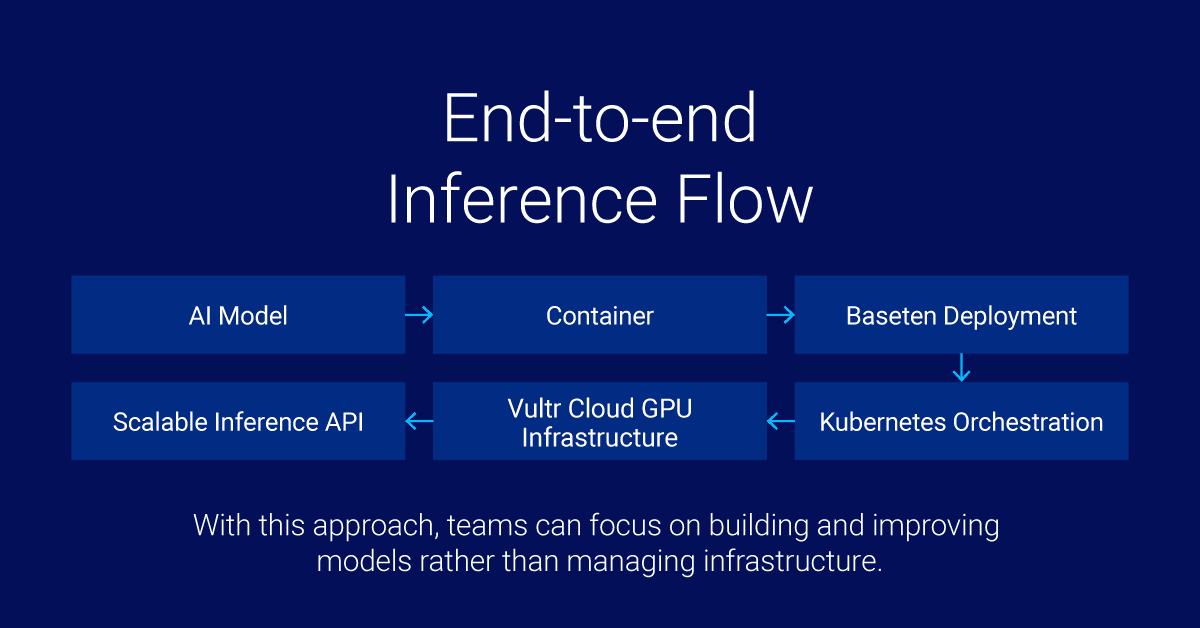
Running production inference requires more than orchestration. It requires a complete stack that includes scalable compute, model deployment tooling, and operational infrastructure.
Vultr and Baseten provide a combined platform that simplifies the deployment and scaling of AI inference workloads.
The stack works as follows:
- Vultr Cloud GPUs and Bare Metal provide the compute layer for AI workloads.
- Kubernetes clusters on Vultr orchestrate containerized model services.
- Baseten manages model deployment, versioning, and inference APIs.
This architecture allows organizations to deploy models quickly while maintaining the flexibility and scalability required for production AI.
A typical deployment workflow looks like this:
- Deploy GPU-enabled Kubernetes clusters on Vultr.
- Package machine learning models into containers.
- Deploy models through Baseten.
- Kubernetes automatically orchestrates and scales inference endpoints.
The resulting architecture enables low-latency, production-ready inference services.
Example use cases
Organizations across industries are adopting AI inference to power real-time decision systems and intelligent applications. The Vultr and Baseten stack enables these workloads to run reliably at scale.
Financial services
Banks and payment providers can deploy AI-powered support agents that triage incoming requests in real time. Models classify requests into categories such as fraud investigations, disputes, or payment operations, helping support teams respond faster while reducing operational overhead.
Energy and infrastructure
Energy companies process large volumes of operational data from sensors, monitoring systems, and grid infrastructure. AI inference systems can analyze this data continuously to detect anomalies, predict maintenance needs, and improve operational efficiency.
Healthcare
Healthcare providers and digital health platforms can deploy AI systems to analyze medical records, automate documentation workflows, or provide clinical decision support to clinicians. Kubernetes-based infrastructure allows these services to scale while maintaining reliability and performance.
Building production AI infrastructure
As AI moves from experimentation to production, infrastructure becomes a critical factor in success. Teams need platforms that can reliably deploy, scale, and operate AI systems across environments.
Kubernetes provides the orchestration layer for managing AI workloads, while Vultr delivers scalable GPU infrastructure, and Baseten simplifies model deployment and inference management.
Together, this stack enables organizations to run production AI systems with the flexibility, performance, and scalability modern applications require.