

As AI models grow in size and complexity, memory demands are scaling rapidly. AMD Instinct™ MI325X GPUs, featuring 256GB of high-bandwidth HBM3e, are purpose-built to meet the demands of today’s large-scale workloads. This includes memory-heavy workloads like PPO-based reinforcement learning, where actor and critic models run parallel with long sequences and rollouts. Even fine-tuning a 7B model can require over 800GB of HBM, making multi-node clusters essential.
Vultr now offers AMD Instinct MI325X- and MI300X-based bare metal instances, making accessing high-performance GPUs for advanced AI workloads easier.
Designed for modern AI infrastructure
dstack is an open-source orchestrator purpose-built for AI as a streamlined alternative to Kubernetes and Slurm. Lightweight and optimized for running containers on AMD GPU clusters, it simplifies orchestration across both VM and bare metal AMD clusters so teams can focus on model development, not infrastructure.

SSH-based fleet management
dstack supports both Vultr’s on-demand AMD instances and reserved clusters with high interconnectivity. To use interconnected AMD clusters, use dstack SSH fleets.
Once dstack’s control plane is set up, getting started on AMD GPU clusters is simple. Define an SSH-based fleet using the hostnames and cluster node credentials, then use the dstack “apply CLI” command. Once activated, teams can schedule distributed training workloads cost-effectively, leveraging containers.
dstack supports torchrun, Hugging Face Accelerate, Ray, and more, providing the flexibility to use your preferred stack.
Monitoring cluster health and performance
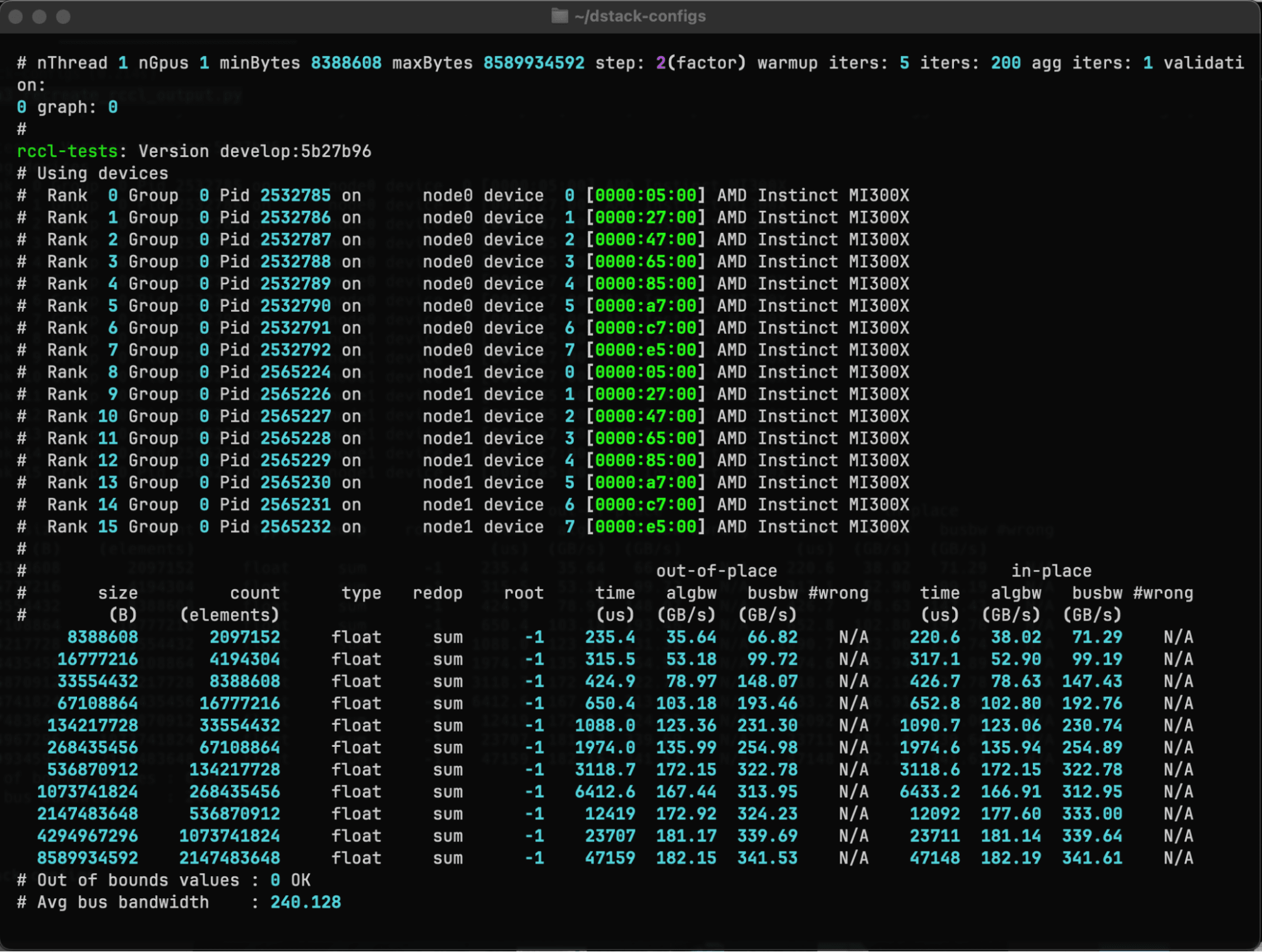
Validating inter-GPU communication
Reliable communication is key for distributed training. Use RCCL-based MPI tests with dstack to validate inter-node and inter-GPU bandwidth and eliminate bottlenecks before full-scale training.
Real-time GPU utilization
dstack surfaces real-time metrics – GPU usage, memory, network throughput – via UI and CLI. This visibility helps optimize performance and minimize idle time.
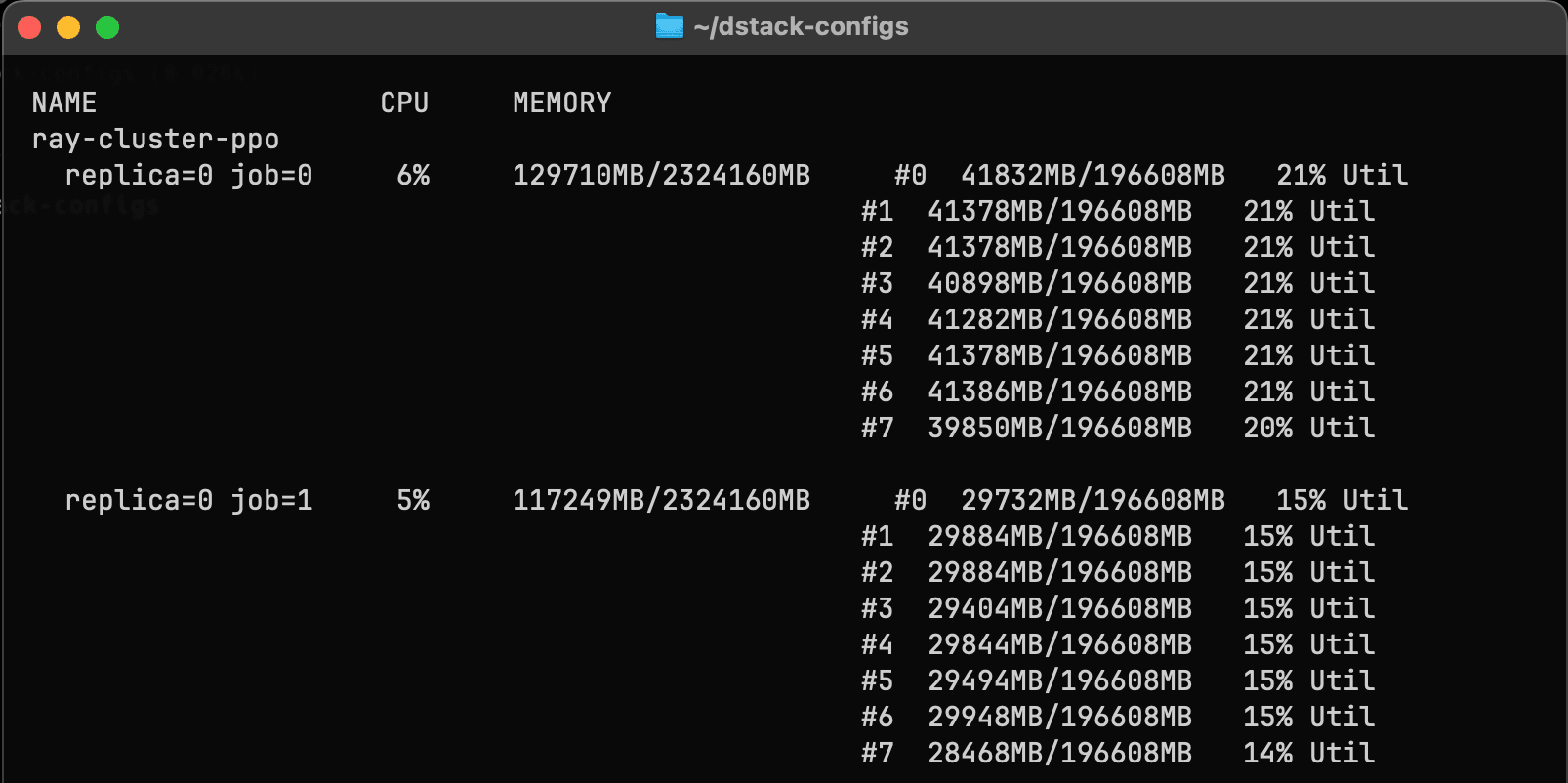
dstack also supports auto-termination policies for workloads with low or idle GPU usage, helping to reduce wasted compute and manage costs effectively.
Ecosystem compatibility
dstack is container-native and works with existing Docker images. It integrates cleanly with open-source tools like TRL, Axolotl, Verl, and more, giving researchers full flexibility while maintaining performance on AMD Instinct™ GPUs.
Try it out
Whether you’re building RL pipelines, fine-tuning LLMs, or training models from scratch, dstack and AMD Instinct™ GPUs on Vultr make a powerful combination for next-gen AI infrastructure.
For a step-by-step guide to running distributed training on Vultr’s AMD GPU clusters with dstack.
Tutorial: Distributed Training on AMD Instinct™ MI325X Clusters with dstack